
Welcome to Perceptron, TechCrunch’s weekly roundup of AI news and research from around the world. Machine learning is a key technology in practically every industry now, and there’s far too much happening for anyone to keep up with it all. This column aims to collect some of the most interesting recent discoveries and papers in the field of artificial intelligence — and explain why they matter.
(Formerly known as Deep Science; check out previous editions here.)
This week’s roundup starts with a pair of forward-thinking studies from Facebook/Meta. The first is a collaboration with the University of Illinois at Urbana-Champaign that aims at reducing the amount of emissions from concrete production. Concrete accounts for some 8 percent of carbon emissions, so even a small improvement could help us meet climate goals.

This is called “slump testing.”
What the Meta/UIUC team did was train a model on over a thousand concrete formulas, which differed in proportions of sand, slag, ground glass, and other materials (you can see a sample chunk of more photogenic concrete up top). Finding the subtle trends in this dataset, it was able to output a number of newformulas optimizing for both strength and low emissions. The winning formula turned out to have 40 percent less emissions than the regional standard, and met… well, some of the strength requirements. It’s extremely promising, and follow-up studies in the field should move the ball again soon.
The second Meta study has to do with changing how language models work. The company wants to work with neural imaging experts and other researchers to compare how language models compare to actual brain activity during similar tasks.
In particular, they’re interested in the human capability of anticipating words far ahead of the current one while speaking or listening — like knowing a sentence will end in a certain way, or that there’s a “but” coming. AI models are getting very good, but they still mainly work by adding words one by one like Lego bricks, occasionally looking backwards to see if it makes sense. They’re just getting started but they already have some interesting results.
Back on the materials tip, researchers at Oak Ridge National Lab are getting in on the AI formulation fun. Using a dataset of quantum chemistry calculations, whatever those are, the team created a neural network that could predict material properties — but then inverted it so that they could input properties and have it suggest materials.
“Instead of taking a material and predicting its given properties, we wanted to choose the ideal properties for our purpose and work backward to design for those properties quickly and efficiently with a high degree of confidence. That’s known as inverse design,” said ORNL’s Victor Fung. It seems to have worked — but you can check for yourself by running the code on Github.
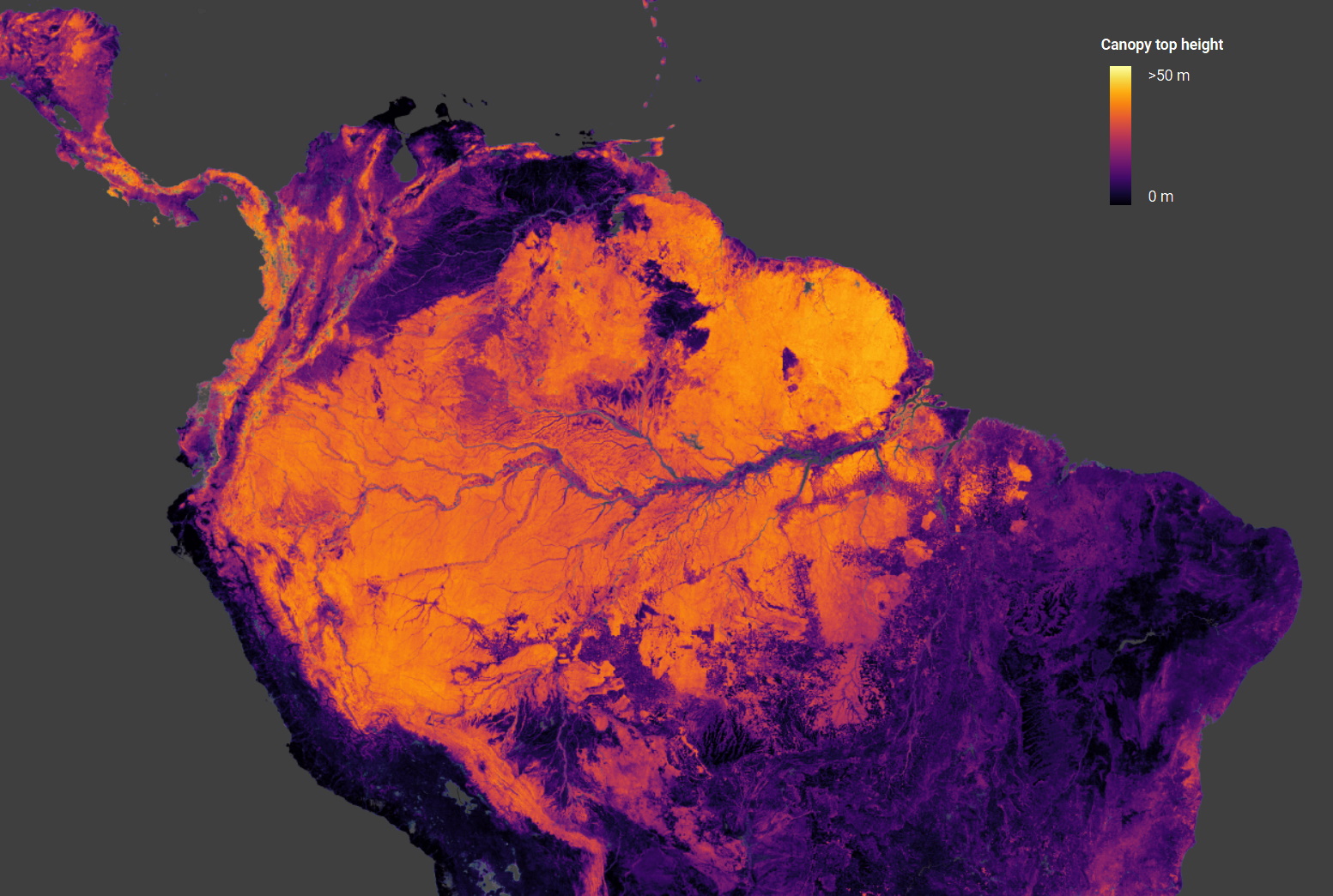
Image Credits: ETHZ
Concerned with physical predictions on an entirely different scale, this ETHZ project estimates the heights of tree canopies around the globe using data from ESA’s Copernicus Sentinel-2 satellites (for optical imagery) and NASA’s GEDI (orbital laser ranging). Combining the two in a convolutional neural network results in an accurate global map of tree heights up to 55 meters tall.
Being able to do this kind of regular survey of biomass at a global scale is important for climate monitoring, as NASA’s Ralph Dubayah explains: “We simply do not know how tall trees are globally. We need good global maps of where trees are. Because whenever we cut down trees, we release carbon into the atmosphere, and we don’t know how much carbon we are releasing.”
You can easily browse the data in map form here.
Also pertaining to landscapes is this DARPA project all about creating extremely large-scale simulated environments for virtual autonomous vehicles to traverse. They awarded the contract to Intel, though they might have saved some money by contacting the makers of the game Snowrunner, which basically does what DARPA wants for $30.

Image Credits: Intel
The goal of RACER-Sim is to develop off-road AVs that already know what it’s like to rumble over a rocky desert and other harsh terrain. The 4-year program will focus first on creating the environments, building models in the simulator, then later on transferring the skills to physical robotic systems.
In the domain of AI pharmaceuticals, which has about 500 different companies right now, MIT has a sane approach in a model that only suggests molecules that can actually be made. “Models often suggest new molecular structures that are difficult or impossible to produce in a laboratory. If a chemist can’t actually make the molecule, its disease-fighting properties can’t be tested.”
Looks cool, but can you make it without powdered unicorn horn?
The MIT model “guarantees that molecules are composed of materials that can be purchased and that the chemical reactions that occur between those materials follow the laws of chemistry.” It kind of sounds like what Molecule.one does, but integrated into the discovery process. It certainly would be nice to know that the miracle drug your AI is proposing doesn’t require any fairy dust or other exotic matter.
Another bit of work from MIT, the University of Washington, and others is about teaching robots to interact with everyday objects — something we all hope becomes commonplace in the next couple decades, since some of us don’t have dishwashers. The problem is that it’s very difficult to tell exactly how people interact with objects, since we can’t relay our data in high fidelity to train a model with. So there’s lots of data annotation and manual labeling involved.
The new technique focuses on observing and inferring 3D geometry very closely so that it only takes a few examples of a person grasping an object for the system to learn how to do it itself. Normally it might take hundreds of examples or thousands of repetitions in a simulator, but this one needed just 10 human demonstrations per object in order to effectively manipulate that object.

Image Credits: MIT
It achieved an 85 percent success rate with this minimal training, way better than the baseline model. It’s currently limited to a handful of categories but the researchers hope it can be generalized.
Last up this week is some promising work from Deepmind on a multimodal “visual language model” that combines visual knowledge with linguistic knowledge so that ideas like “three cats sitting on a fence” have a sort of crossover representation between grammar and imagery. That’s the way our own minds work, after all.
Flamingo, their new “general purpose” model, can do visual identification but also engage in dialogue, not because it’s two models in one but because it marries language and visual understanding together. As we’ve seen from other research organizations, this kind of multimodal approach produces good results but is still highly experimental and computationally intense.
Powered by WPeMatico




