
If you’ve used a smart voice assistant such as Alexa, Siri and whatever-Google’s-smart-assistant-is-called, you’ll probably have noticed that the tech is getting smarter every day. Google can wait on hold for you, Siri can speak in a gender-neutral voice and Alexa can read you bedtime stories in your dead grandmother’s voice. Robotics is evolving in leaps and bounds as well, as we explored in our Robotics event last month. The gap between the two — voice commands and autonomous robotics — has been vast, for a number of reasons. Last week, we went to Google’s robotics labs in Mountain View to see how that’s set to change in the near future.
Teaching robots what to do for repetitive tasks in controlled spaces where humans aren’t allowed isn’t easy, but it’s more or less a solved problem. Rivian’s recent factory tour was a great reminder of that, but the use of industrial robotics is everywhere in manufacturing.
General-purpose robots that are able to solve lots of different tasks based on voice commands in spaces where humans also exist, is a lot harder. You might say, “But what about Roomba,” but everyone’s favorite robo-vacuum is generally programmed to avoid touching things other than the floor, and whatever’s on the floor — much to some owners’ chagrin.

Table tennis is a game where the robot can easily self-determine whether a task was successful and learn from its mistakes. Here, one of the robotics researchers at Google is taking a break, showing the robot what’s what. Image Credits: Haje Kamps (opens in a new window) / TechCrunch(opens in a new window)
“You may wonder why ping-pong. One of the big challenges in robotics today is this intersection of being fast, precise and adaptive. You can be fast and not adaptive at all; that’s not a problem. That’s fine in an industrial setting. But being fast and adaptive and precise is a really big challenge. Ping-pong is a really nice microcosm of the problem. It requires precision and speed. You can learn from people playing: it’s a skill that people develop by practicing,” Vincent Vanhoucke, Distinguished Scientist and head of robotics at Google Research told me. “It’s not a skill where you can read the rules and become a champion overnight. You have to really practice it.”
Speed and precision is one thing, but the nut Google is really trying to crack in its robotic labs, is the intersection between human language and robotics. It is making some impressive leaps in the level of robotic understanding natural language that a human might use. “When you have a minute, could you grab me a drink from the counter?” is a pretty straightforward request that you might ask a human. To a machine, however, that statement wraps a lot of knowledge and understanding into a seemingly single question. Let’s break it down: “When you have a minute” could mean nothing at all, just meant as a figure of speech, or it could be an actual request to finish what the robot is doing. If a robot is being too literal, the “correct” answer to “could you grab me a drink” could just be the robot saying “yes”. It can, and it confirms that it is able to grab a drink. But, as the user, you didn’t explicitly ask the robot to do it. And, if we’re being extra pedantic, you didn’t explicitly tell the robot to bring you the drink.
These are some of the issues that Google is tackling with its natural language processing system; the Pathways Language Model — or PaLM among friends: Accurately processing and absorbing what a human actually wants, rather than literally doing what they say.
The next challenge is recognizing what a robot is actually able to do. A robot may understand perfectly well when you ask it to grab a bottle of cleaner from the top of the fridge, where it is safely stored out of the way of children. The problem is, the robot can’t reach that high. The big breakthrough is what Google is calling “affordances” — what can the robot actually do with some reasonable degree of success. This might include easy tasks (“move a meter forward”), slightly more advanced tasks (“Go find a can of Coke in the kitchen”), to complex, multi-step actions that require the robot to show quite a bit of understanding of its own abilities and the world around it. (“Ugh, I spilled my can of Coke on the floor. Could you mop it up and bring me a healthy drink?”).
Google’s approach uses the knowledge contained in language models (“Say”) to determine and score actions that are useful for high-level instructions. It also uses an affordance function (“Can”) that enables real-world-grounding and determines which actions are possible to execute in a given environment. Using the PaLM language model, Google is calling that PaLM-SayCan.

Google’s robotics lab is using a number of these robots from Everyday Robots. These chaps are taking a well-deserved R&R (rest and recharge), and they’ve even learned how to plug themselves in for recharging. Image Credits: Haje Kamps (opens in a new window) / TechCrunch(opens in a new window)
To solve the more advanced command above, the robot has to break it down into a number of individual steps. One example of that might be:
- Come to the speaker.
- Look at the floor, find the spill, remember where it is.
- Go through the drawers, cabinets and kitchen counters looking for a mop, sponge or paper towel.
- Once a cleaning tool (there is a sponge in the drawer) is found, pick it up.
- Close the drawer.
- Move to the spill.
- Clean up the spill, monitoring whether the sponge can absorb all the liquid. If not, go wring it out in the sink, and come back.
- Once the spill is cleaned, wring the sponge one more time.
- Turn on the tap, rinse the sponge, turn off the tap, wring the sponge one last time.
- Open drawer, put sponge away, close drawer.
- Identify what drinks are in the kitchen, and somehow determine which drinks are “healthier” than a Coke.
- Find a bottle of water in the fridge, pick it up, bring it to the person who asked for it — who may have moved since they asked the question, because you’re a slow-poke little robot that had to roll back and forth to the sink 14 times, because instead of using paper towels, you thought it’d be a brilliant idea to use a little kitchen sponge to mop up 11 ounces of liquid.
Anyway — I’m poking fun here, but you get the gist; even relatively simple-sounding instructions can, in fact, include a large number of steps, logic and decisions along the way. Do you find the healthiest drink around, or is the goal to get anything that’s healthier than Coca-Cola? Might it make sense to get the drink first, and then mop up the mess, so the human can have their thirst quench while you figure out the rest of the task?
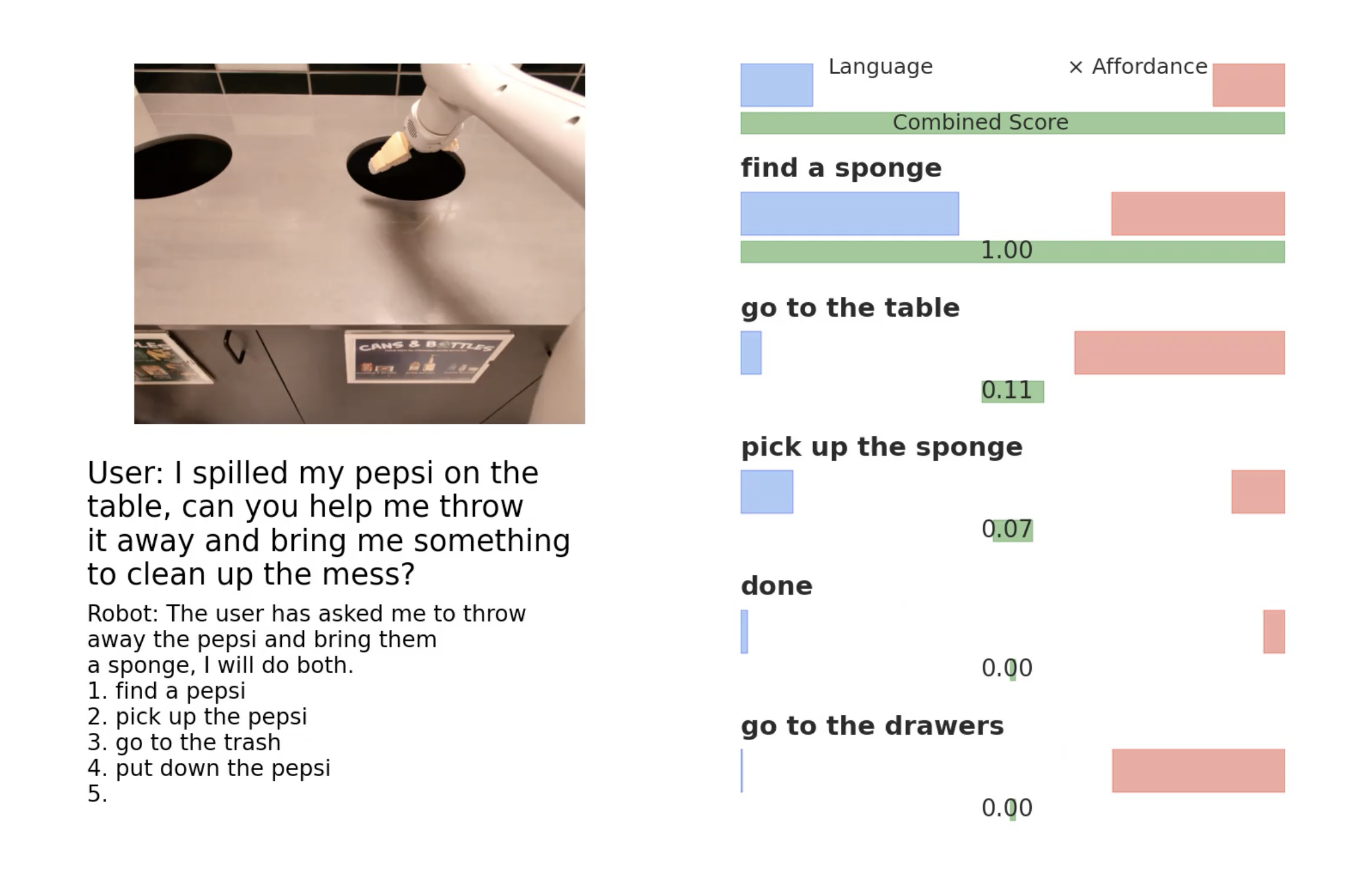
This screenshot shows how the robot might evaluate a query and figure out what it should do at every step of the way. In this case, the robot determined that it should find a sponge, and that it has a high degree of success in finding, identifying and manipulating sponges. It also shows that this particular robot is really good at “going to drawers,” but also concludes that that wouldn’t be all that helpful in this instance. Image Credits: Google
The crucial thing here is to teach the robots what they can and can’t do, and what makes sense in various situations. Touring the Google robotics lab, I saw 30-odd robots, both from Everyday Robots and more purpose-built machines, playing table tennis, catching lacrosse balls and learning to stack blocks, open fridge doors and “being polite” while operating in the same space as humans.

Nice catch! Image Credits: Haje Kamps (opens in a new window) / TechCrunch
The interesting challenge that robotics faces is that language models aren’t inherently grounded in the physical world. They are trained on huge libraries of text, but text libraries don’t interact with their environments, nor do they have to worry too much about causing issues. It’s kinda funny when you ask Google to direct you to the nearest coffee shop, and Maps accidentally maps out a 45-day hike and a three-day swim across a lake. In the real world, silly mistakes have real consequences.
For example, when prompted with “I spilled my drink, can you help?” the language model GPT-3 responds with “You could try using a vacuum cleaner.” It makes sense: For some messes, a vacuum cleaner is a good choice, and it stands to reason that a language model associates a vacuum cleaner with, well, cleaning. If the robot actually did that, it would likely fail: Vacuums aren’t great at spilled drinks, and water and electronics don’t mix, so you might end up with a broken vacuum at best, or an appliance fire at worst.
Google’s PaLM-SayCan-enabled robots are placed in a kitchen setting, and are trained to get better at various aspects of being helpful in a kitchen. The robots, when given an instruction, are trying to make a determination. “What is the likelihood of me being successful at the thing I’m about to try,” and “how helpful is this thing likely to be.” Somewhere in the space between those two considerations, robots are getting significantly smarter by the day.

The triumphant return of the sponge-fetching robot. Image Credits: Haje Kamps (opens in a new window) / TechCrunch
Affordances — or the ability to do something — isn’t binary. Balancing three golf balls on top of each other is very hard, but not impossible. Opening a drawer is almost impossible for a robot that hasn’t been shown how drawers work — but once they are trained, and are able to experiment with how to best open a drawer, they can get a higher and higher degree of confidence in a task. An untrained robot, Google suggests, might not be able to grab a bag of potato chips from a drawer. But give it some instructions and a few days to practice, and the chance of success goes up significantly.
Of course, all of this training data is scored as the robot is trying things out. From time to time, a robot may “solve” a task in a surprising way, but it may actually be “easier” to do it that way for a robot.
By divorcing the language models from the affordances, it means that the robot can “understand” commands in a number of different languages. The team demonstrated that in the kitchen, too, when head of robotics Vincent Vanhoucke asked the robot for a can of Coke in French; “We got the language skills for free,” the team said, highlighting how the neural networks that are being used to train the robots are flexible enough to open new doors (literally and figuratively) for accessibility and universal access.

Most robots that touch, open, move and clean things aren’t generally invited to operate this close to humans. We were encouraged to keep our distance, but the researchers seemed very at home with the robots operating autonomously within inches of their non-armored human bodies. Image Credits: Haje Kamps (opens in a new window) / TechCrunch
None of the robots or technologies are currently available, or necessarily even destined, for commercial products.
“Right now, it’s entirely research. As you can see from the skill level we have today, it’s not really ready to be deployed in a commercial environment. We are research outfits, and we love to work on things that don’t work,” quips Vanhoucke. “That’s the definition of research in some ways, and we’re going to keep pushing. We like to work on things that don’t need to scale because it’s a way of informing how things scale with more data and more computer abilities. You can see a trend of where things might go in the future.”
It’s going to take Google’s robotics lab a while to figure out what, if any, commercial impacts of its experiments will be in the long run, but even in the relatively simple demos shown in Mountain View last week, it’s obvious that natural language processing and robotics both win as Google’s teams build deeper skills, knowledge and vast datasets in how to train robots.
Powered by WPeMatico




